Indirect Supervision for Relation Extraction Using Question-Answer Pairs
Zeqiu Wu, Xiang Ren, Frank F. Xu, Ji Li, Jiawei Han. WSDM 2018.
Task Overview
Typically, relation extraction (RE) systems rely on training data, primarily acquired via human annotation, to achieve satisfactory performance. To alleviate the exhaustive process of human labeling, the recent trend has deviated towards the adoption of distant supervision (DS). However, the noise introduced to the automatically generated training data is not negligible. Towards the goal of diminishing the negative effects by noisy DS training data, some distantly supervised RE models design distinct assumptions to remove redundant training information. However, these models mostly address only one type of error and do not use any trustworthy information sources outside the noisy training corpus itself. We aim to handle these two remaining issues of distant supervised relation extraction.
Our Method
We address the above issues as follows:
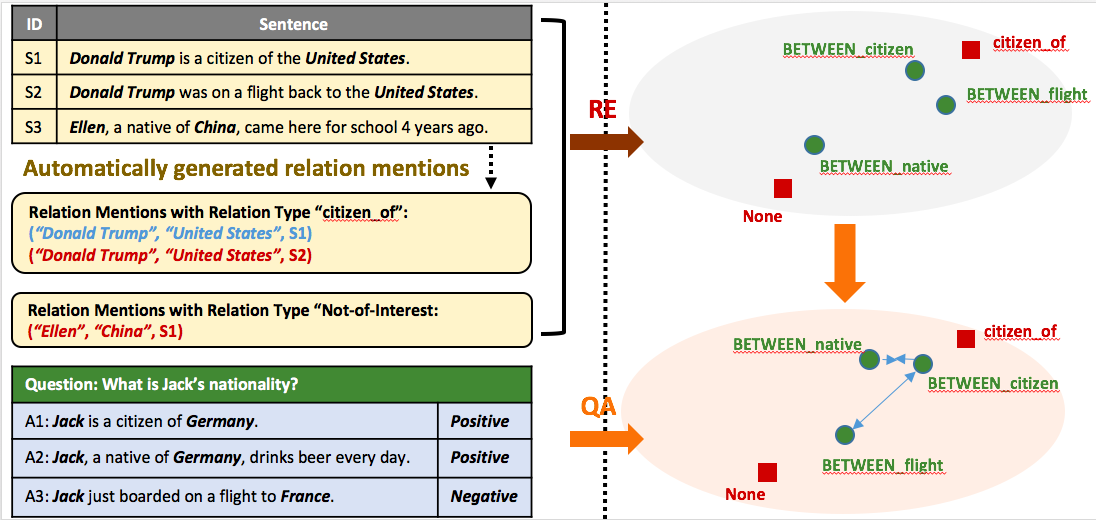
- We integrate indirect supervision from another same-domain data source in the format of QA sentence pairs, that is, each question sentence maps to several positive (where a true answer can be found) and negative (where no answer exists) answer sentences. For example, in the following graph, we have two positive answer sentences (A1, A2) and one negative answer sentence (A3) for the question “What is Jack’s nationality”. We adopt the principle that for the same question, positive pairs of (question, answer) should be semantically similar while they should be dissimilar from negative pairs. In the question “What is Jack’s nationality”, we identify “Jack” to be the question entity mention. In both A1 and A2, we extract both the question entity mention and the answer entity mention and construct 2 entity mention pairs: (“Jack”, “Germany”, A1) and (“Jack”, “Germany”, A2). In a negative sentence like A3, we randomly sample entity mention pairs as negative examples. In this example, we only have (“Jack”, “France”, A3). Based on our hypothesis, (“Jack”, “Germany”, A1) and (“Jack”, “Germany”, A2) should be very close in the embedding space while either of them should be far away from (“Jack”, “France”, A3).
- Instead of differentiating types of labeling errors at the instance level, we concentrate on how to better learn semantic representation of features. Wrongly labeled training examples essentially misguide the understanding of features. It increases the risk of having a non-representative feature learned to be close to a relation type and vice versa. Therefore, if the feature learning process is improved, potentially both types of error can be reduced. How QA pairs can help improve the feature learning process is illustrated on the right side of the following graph.
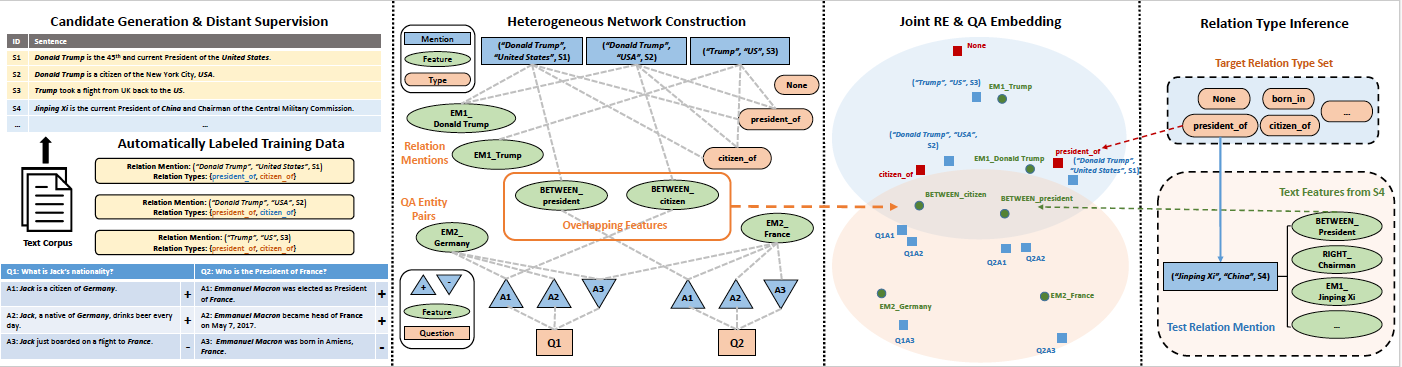
Framework
- Generate text features for each relation mention or QA entity
mention pair, and construct a heterogeneous graph using four
kinds of objects in combined corpus, namely relation mentions
from RE corpus, entity mention pairs from QA corpus, target relation
types and text features to encode aforementioned signals
in a unified form. (Heterogeneous Network Construction)
- Jointly embed relation mentions, QA pairs, text features, and
type labels into two low-dimensional spaces connected by shared
features, where close objects tend to share the same types or
questions. (Joint RE & QA Embedding)
- Estimate type labels r for each test relation mention z from
learned embeddings, by searching the target type set R. (Relation Type Inference)
Performance
We evaluated our model on two relation extraction datasets: NYT and KBP, with TREC QA dataset.
The table includes performance comparison with several relation extraction systems over KBP 2013 dataset (sentence-level extraction):
| Method | Precision | Recall | F1 |
|---|---|---|---|
| Mintz (our implementation, Mintz et al., 2009) | 0.296 | 0.387 | 0.335 |
| LINE + Dist Sup (Tang et al., 2015) | 0.360 | 0.257 | 0.299 |
| MultiR (Hoffmann et al., 2011) | 0.325 | 0.278 | 0.301 |
| FCM + Dist Sup (Gormley et al., 2015) | 0.151 | 0.498 | 0.300 |
| CoType-RM (Ren et al., 2017) | 0.342 | 0.339 | 0.340 |
| ReQuest (Wu et al., 2018) | 0.386 | 0.410 | 0.397 |
Resources
Codes and datasets have been uploaded to Github
Reference
Please cite the following paper if you find the codes and datasets useful:
@inproceedings{wu2018request,
author = {Wu, Zeqiu and Ren, Xiang and Xu, Frank F. and Li, Ji and Han, Jiawei},
title = {Indirect Supervision for Relation Extraction Using Question-Answer Pairs},
booktitle = {Proc. WSDM},
year = {2018},
}